

You can’t go to a business-focused conference these days with someone talking about how Artificial Intelligence and Machine Learning are the future, but it’s pretty clear they aren’t reality yet.
I’m fascinated by the upside of AI/ML, but I haven’t seen much ROI in many industrial settings yet. Why the disappointment? It’s because of the Data Pyramid. Let’s talk about the Data Pyramid, plus walk through an example of how to climb it to get to the sweet, sweet, tasty AI and ML.
I started my oil and gas career running reservoir simulation models at ExxonMobil – they were complex to set up, required astonishing amounts of input assumptions, and took days to run in many cases. I learned a lot about reservoir characterization, economics, and well behavior, but my single biggest lesson? Garbage In, Garbage Out.
The Data Pyramid is just a fancy way of understanding Garbage In, Garbage Out, but it’s structured to help us understand where the real work is. Each layer is built on the one below it, and if you don’t get the foundation right, trying to reach the top is likely to be a waste of time and money.
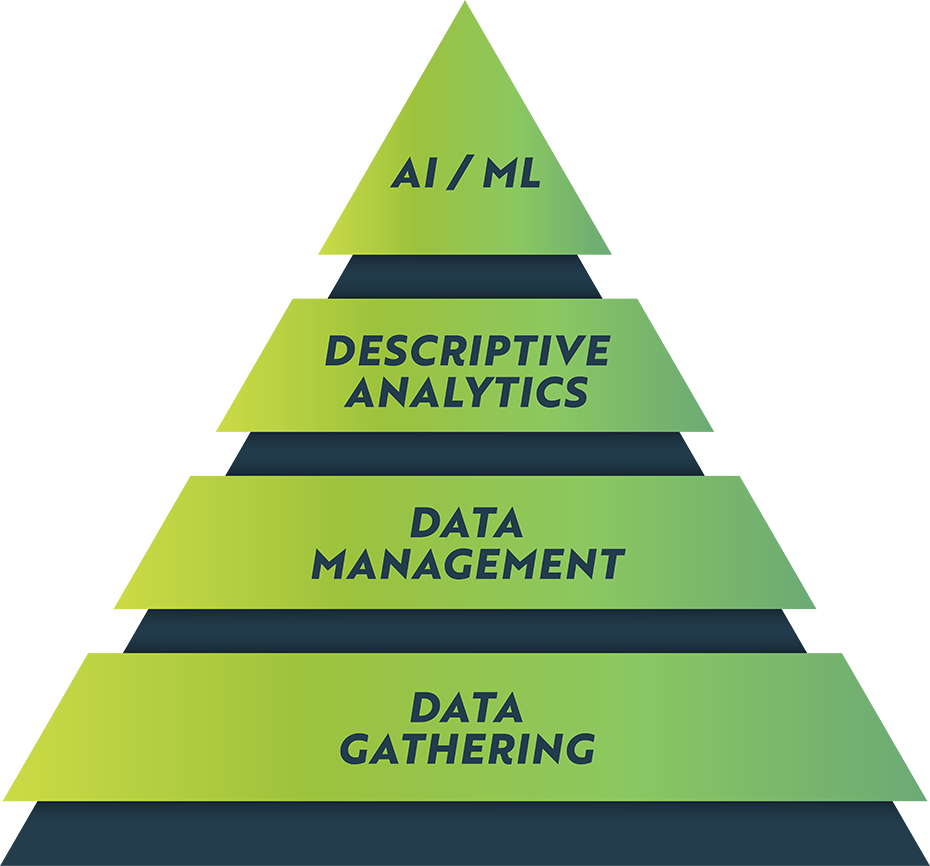
Data Gathering
At the bottom, we see that Data Gathering is a huge chore – in a typical O&G company, at least half of the employees are doing it. From pumpers to revenue accountants, reserves engineers to land administrators, people are spending time recording data on an activity, a measurement, a transaction, an assumption. Lots of data is coming in, from lots of sources, and landing in lots of systems.
Data Management
Data Management is usually where IT steps in. It’s decidedly unsexy work – ensuring quality rules are followed, integrating source systems, reconciling well lists and vendor lists, and on and on. Lots of great ideas crash and burn at this stage. The data exists, but isn’t formatted, structured, complete, or clean. If you haven’t built a data management strategy for your fancy AI/ML idea, you aren’t gonna make it past this level. Think of this as Von Kaiser from Mike Tyson’s Punch-Out!! Pretty straightforward, kinda boring, but you have to follow the rules and pay attention.
Descriptive Analytics
Descriptive Analytics are when things start to get fun! Now we’re entering the territory of understanding and explaining the past – this is a great place to explore and test ideas in simple ways. Which rig has less Non-Productive Time? How much did we spend last month? Which leases are at risk of expiry?
So why do we need to stop at Descriptive Analytics before moving up to AI and ML? Because we need coherent hypotheses.
AI/Machine Learning
Just like fancy reservoir simulators and middle school science projects, Artificial Intelligence and Machine Learning are at their best when you have an objective, testable, quantifiable hypothesis. While there are certainly algorithms that build black-box hypotheses on their own, they are very, very difficult to use in decision-making. They lack explainability (repping Deanna Zhang once again) and can end up predicting things that O&G executives are inherently, and appropriately, suspicious of.
I’m reminded of a presentation I saw a few years ago – a smart young engineer used an ensemble of AI algorithms which predicted that for every pound of additional sand, the wells got *increasingly* better. The implication being that an infinitely sized frac job would produce an infinite amount of oil. He didn’t believe that, of course. But by having the graph in his slides, his work lost credibility. Writing down a hypothesis just takes a few minutes, but it builds confidence and focus. It’s a step you shouldn’t skip.
ThoughtTrace is an interesting example.
Thought Trace is an AI/ML-backed natural language processing tool for complex contracts like oil and gas leases. They aren’t paying me to say this, but their product is a great example of how the Data Pyramid works in action. They have strong technology and a sound business, but the real secret is that they execute each step:
- Data Gathering is in the form of each lease, JOA, or other document, scanned with reasonable quality into a PDF. Most companies already have this in hand, or can affordably build it with outsourced scanning services.
- Data Management is handled with careful building of primary keys to make the data usable downstream. PDFs have to be attached to lease records. This work is typically done by hand inside the E&P company, but it’s a step that can’t be skipped. Von Kaiser returns.
- Descriptive Analytics is fairly hidden from the end users, but a workflow like this only runs if you’ve spent the time behind the scenes, coding and classifying lease language to feed to the AI algorithms above. Without a clear understanding of the various forms of a Pugh clause, the explainability would be missing and the whole thing falls apart.
- At the top of the pyramid, the AI and ML can now do its work. Complex lease language can be parsed, classified, and coded into usable metadata. It all relies on the lower levels of the pyramid – without all that fairly invisible work, the technology would be all Glass Joe, no Mr. Dream.
By using the Data Pyramid to think through their work, industrial companies of all types can get real ROI on AI/ML projects. Special thanks go to Sean Kristjansson for conversations over coffee and beer about these issues over the last few years.
Want to discuss more?
We actually *enjoy* those lower levels of the pyramid and help companies navigate them faster and more effectively.